
Researchers from a number of disciplines can now use a billion-scale dataset of tweets from around the world to answer their research questions about the COVID-19 pandemic.
Assistant professor Muhammad Abdul-Mageed and his team in the UBC iSchool (school of information) and department of linguistics developed Mega-COV, a longitudinal, publicly available dataset of 1.5 billion tweets in 104 languages.
Abdul-Mageed, a UBC language sciences research lead, discusses initial analysis of the data, including how Twitter users are interacting directly with one another more than ever, why news stories from Canadian outlets were shared less in 2020 than in previous years, and why this massive dataset is important for future work.
What is the Mega-COV database and why did you create it?
Mega-COV is a dataset of 1.5 billion tweets designed for studying COVID-19.
We designed Mega-COV to be diverse and inclusive as well as multilingual. The dataset is also longitudinal as the tweets are crawled from 2007 to 2020, making it possible to compare the impact of the pandemic across time. The data are collected from more than 167,000 locations in 268 countries, enabling geographical comparisons. Mega-COV is also linguistically diverse, covering more than 100 languages, including languages for which we do not have many linguistic resources such as Belarusian, Burmese and Kazakh.
COVID-19 affects so many aspects of life. This dataset gives researchers from all disciplines where human communication, behaviour, and well-being are the focus, sufficient data to investigate important research questions and make discoveries about this pandemic.
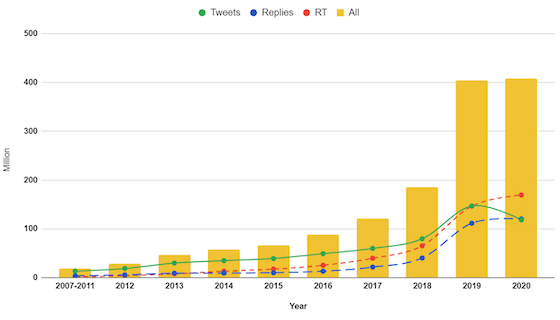
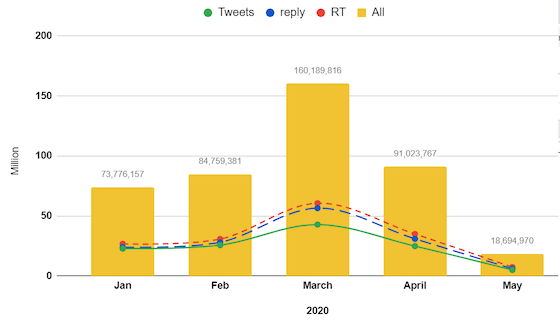
What has early analysis shown?
We found that people flocked to social media to talk about the pandemic and the way it is impacting their lives. March had an incredible surge, with about 40 per cent more posting compared to the same month last year. Based on a sample of one million people, we have found that the number of posts during the first five months of this year have already exceeded the whole of 2019. As well, for the first time in 15 years, people are talking to one another (through replies and direct messages) more than they are they are directly posting.
We also found that people turned to news outlets. Users shared URLs with stories from news sites significantly more than in 2019, resulting in a rise of the ranks of these sites. For example, New York Post, Sky.com, and La Vanguardia all rose at least 96 positions, while Fox News rose 51 positions, in the rankings of the most shared news site URLs on Twitter. This is important, since it helps contextualize existing reports that Fox News has been accused of spreading misinformation.

Canadian sources were shared less: Global News’ rank fell 78 positions and The Star fell 64 positions. Other Canadian sources such as CBC News and Radio-Canada were also shared less by users on Twitter. This is likely due to the outbreak having much less serious health consequences in Canada than in other countries, and users had to seek information about it elsewhere, resorting to international sources.
How can other researchers use this dataset?
The dataset is publicly available on our lab GitHub and could be useful to sociologists, psychologists, journalists, politicians, public health researchers and researchers in machine learning and natural language processing, among others.
Regardless of demographics, the pandemic has affected everyone. However, different groups and places have been affected more than others and hence may be reacting differently. Questions about the extent to which the pandemic has impacted the lives of different communities, how it affects their hopes, relationships, careers, health and more, are all open for investigation. Due to the size of the dataset, you could even try to answer very specific questions such as measuring population well-being in a given city based on a language of interest during a specific week.
Importantly, we wanted to make this data accessible to a wide range of people. We also wanted it to be diverse and representative of different societies and different languages.
Written and released by UBC
